Destination Earth - The explainer Series
SUPERCOMPUTERS:DECODING THE SCIENCE


Supercomputers are made of a large network of smaller computing elements and processing equipment, able to solve problems too complex for an ordinary laptop. In the field of weather prediction, they play an essential role by providing the needed enhanced computing power to run the dynamic Earth System models and to help provide accurate forecasting.
With Destination Earth, the European Union’s new initiative to create Digital Twins of the Earth system, the use of high-performance computing sits at the core of this joint venture, with its share of novel and innovative ideas. To fully grasp the entire particulars, one needs to crack the codes of some of the most elementary characteristics of supercomputing.
What exactly is a supercomputer and what are its main components? What are the associated challenges to address energy efficiency and to keep improving the potential offered by these installations? From nodes, flops, CPUs, GPUs, DPUs or even TPUs, to programming language and programming models, this story depicts the essentials of supercomputers to help capture the main areas where the new Destination Earth initiative will rely on its innovative aspects.
Climate models and the need for computing power


The goal of Destination Earth is to design virtual models of the Earth system that simulates the atmosphere, ocean, ice, and land with unrivaled precision.
How do global climate models work and why do they need enhanced computing power?
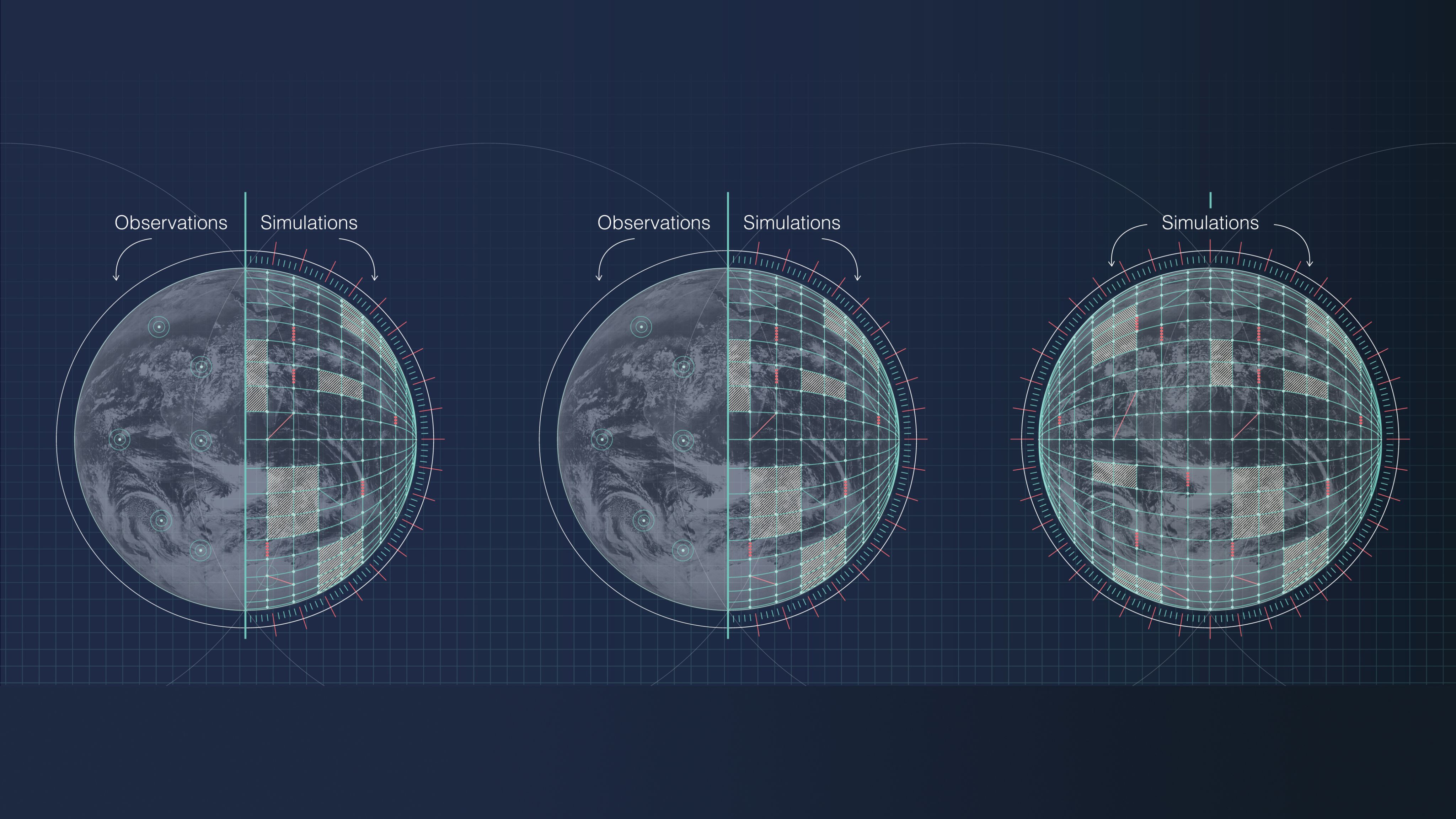
While scientists use models to represent a number of things such as objects, concepts or systems to gain a better understanding of them, global climate models refer to a numerical model gathering physical processes that occur in the atmosphere, ocean, biosphere and land surface.
Fundamentally, theses processes represent how heat, moisture, momentum and chemicals move across space and through time.




These models work by dividing up the Earth’s atmosphere, oceans, lands and sea ice into lots of three dimensional boxes or grid cells.

Weather observations recorded by weather satellites, weather balloons, ocean buoys, and surface weather stations around the world, are collected and fed it at each point of the grid.
The nearer the points are together, the higher resolution the model is, and the better the atmosphere and topography will be represented.

Former Cray cluster installed in ECMWF’s data centre.
Former Cray cluster installed in ECMWF’s data centre.
Taking all the mathematical equations that explain the physics of the atmosphere and calculating them at hundreds of millions of points around the Earth is an enormous job.
This is why these models need vast computing power to complete their calculations in a reasonable amount of time.
Supercomputers for weather prediction: a complex solution for complex problems.


HISTORY
Using computing power to carry out mathematical calculations needed for numerical weather prediction goes back to 1950’s when John von Neumann produced the first computer simulation of the weather. The Electronic Numerical Integrator and Computer (ENIAC) was the most powerful computer available for the project at that time.


ENIAC in BRL building 328. (U.S. Army photo, c. 1947–1955) - ENIAC - Wikipedia
ENIAC in BRL building 328. (U.S. Army photo, c. 1947–1955) - ENIAC - Wikipedia
ARCHITECTURE
The architecture of a supercomputer can be pictured as a congregation of many "laptops", so called computing nodes well connected to each other. These nodes are stacked into cabinets.

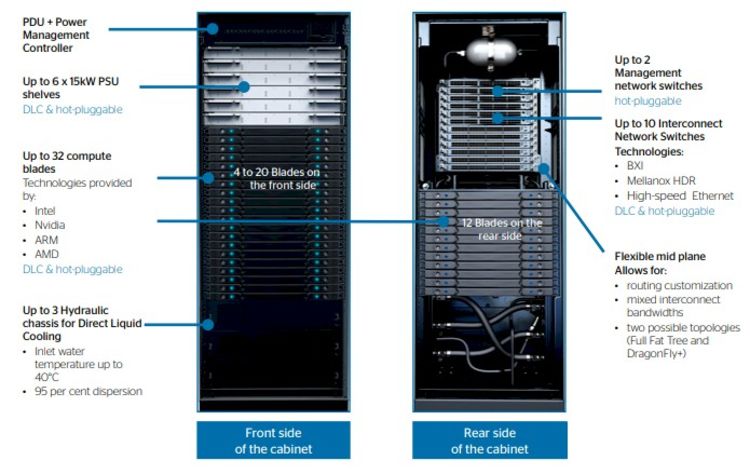
atos-bull-sequana-xh2000-diagram.jpg
atos-bull-sequana-xh2000-diagram.jpg
These cabinets are themselves also multiplied to make a whole forest of cabinets (and including the necessary cooling pipes of such an assembly, as can be seen in the picture), creating the “supercomputer”.


COMPONENTS & CHARACTERISTICS
Supercomputers hardware is similar to a typical personal computer.
Important components include:
CPU


A central processing unit (CPU) is the electronic circuitry that executes instructions. Supercomputers possess hundreds of thousands of processors for performing billions of intensive computations in a single second. These processors produce program instructions to perform calculations and initiate memory access and (pre-) load in caches what they need to process.
But processors take very specific kind of instructions.
Nodes

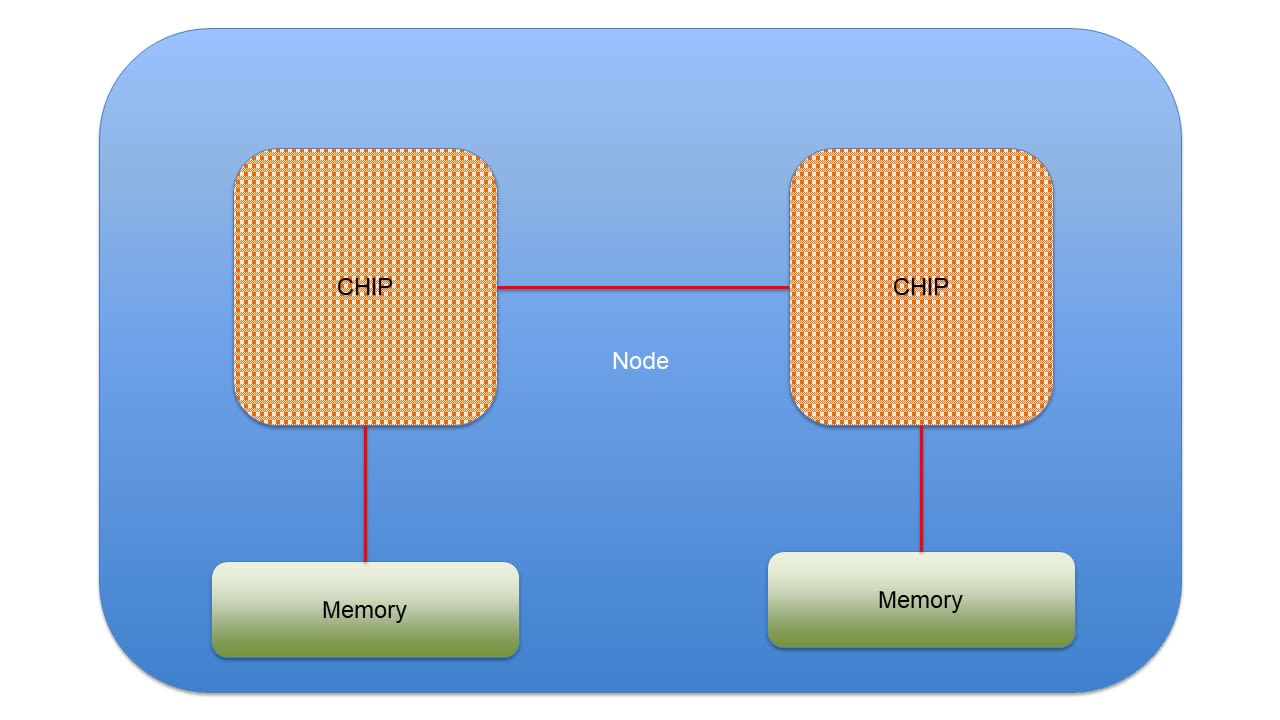
A node is a group of processors and/or accelerators, arrangements that are connected to each other. Modern supercomputers can contain tens of thousands of these nodes.
Memory


Supercomputers feature high volumes of memory, which allow the unit to access information at any given time. A block of memory is packaged with the group of processors on a node.
Compilers
A compiler is a computer program that "translates" the initial human equation, programmed in a pre-defined language known as source code, into a machine code, a set of machine-language instructions that can be understood by the computer’s CPU or accelerator. There are many different types of compilers that produce instructions for specific type of CPUs or accelerators.
Programming language
A Programming language is a human readable way to tell a computer what to do. They fall into two sort of classifications: Low-Level and High-Level.
Low-Level languages are closer to the binary, machine codes. They typically provide little or no abstraction of programming concepts, they can be very fast as they are close to the execution instructions and can give the programmer precise control over how the computer will function. However, they can also be specific to a particular architecture which makes it difficult to use and port to another machine.
General High-Level languages (eg: Fortran, C, Java, Python, C++) are closer to how humans communicate. They define abstract concepts that can be applied and reused in domain specific contexts. While these languages are easier to progam, maintain and port to different platforms, they also take more time for translation into machine code (using compilers) and to optimise the subsequent instructions for the specific HPC hardware.
Flop
Floating-point operations per second, or FLOPS, is the unit of measurement that calculates the performance capability of a supercomputer. One teraFLOPS is equal to 1,000,000,000,000 (one trillion) FLOPS. Exa-scale supercomputers refers to at least one exaFLOPS and is equal to 1,000,000,000,000,000,000 (10^18) FLOPS, or one million teraFLOPS.
The worlds most powerful known computer is Frontier at Oak Ridge National Laboratory in Tennessee, USA. It can sustain over 1.1 ExaFlops – a billion billion flops.



If every one of the 8 Billion people on Earth did one calculation per second, it would take over four years and four months for humans to do the same number of calculations that Frontier can do in one second.


CONNECTIVITY




While computers’ functionalities are multiplied within these installations, their potential offers a wide range of usage options going beyond fast processing only. For example, increased data storage, memory hierarchies with faster and slower data access, but also parallel problem-solving become possible.
To efficiently exploit supercomputers, it is essential to either entirely parallelise a user’s workflow into independent pieces of work, or otherwise manage the entire network and the way the different computers "talk to each other". To orchestrate work across the entire system to match the users’ needs requires to master other skills such as parallel processing.
While an ordinary computer does one thing at a time (serial processing), addressing a distinct series of operations in a certain time, supercomputers work faster by splitting the same problem into independent pieces and working on many pieces at once, which is what is called parallel processing. Send or receive commands reunite these pieces from distributed nodes when necessary.
Parallelisation
“The simultaneous use of more than one processor or computer to solve a problem.”
Parallel computing allows thus for many calculations or processes to be carried out simultaneously. This is essential for numerical weather prediction as it is the key to calculate the multiple points of the spherical grid simultaneously. But there are challenges as to how to synchronise the actions of each parallel node, exchange data between nodes, and provide command and control over the entire parallel cluster.
To get the most out of modern supercomputers, parallelism has to be envisaged through different levels:
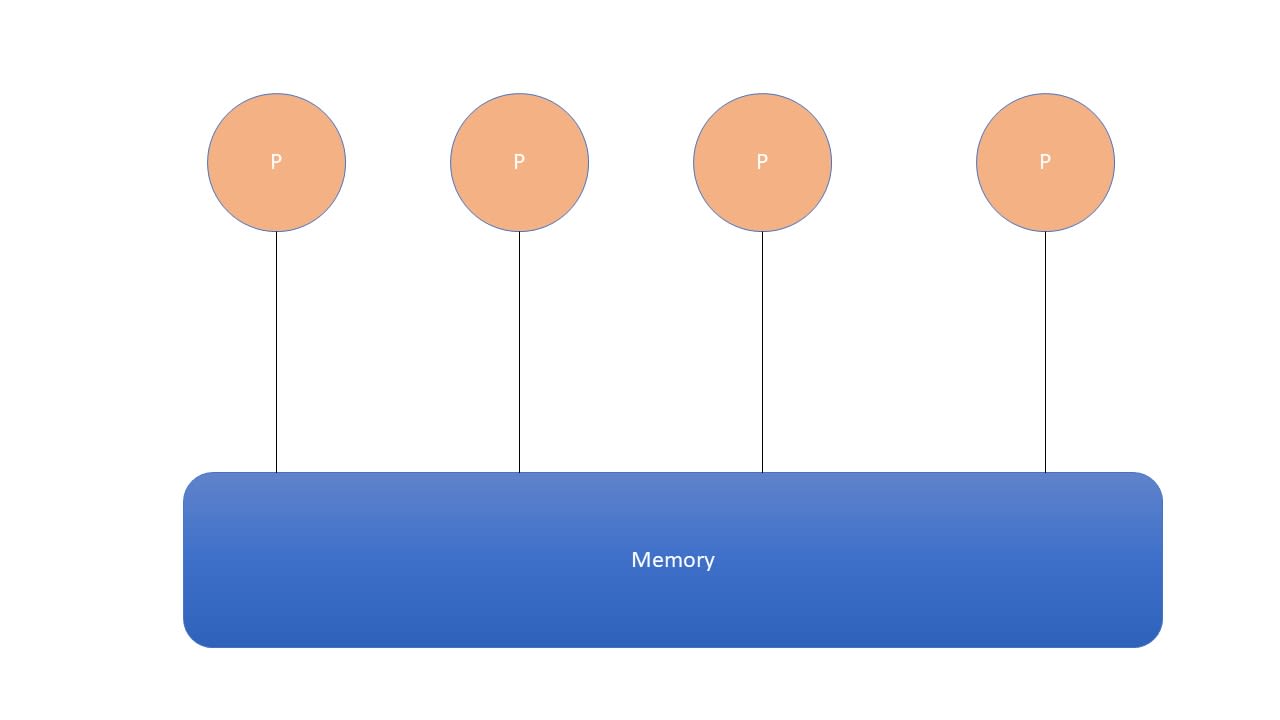
1- At a single node level: several CPUs co-exist on one single node and are sharing the same memory. It is important to utilise the shared memory efficiency but not overwrite the same data whilst doing so.
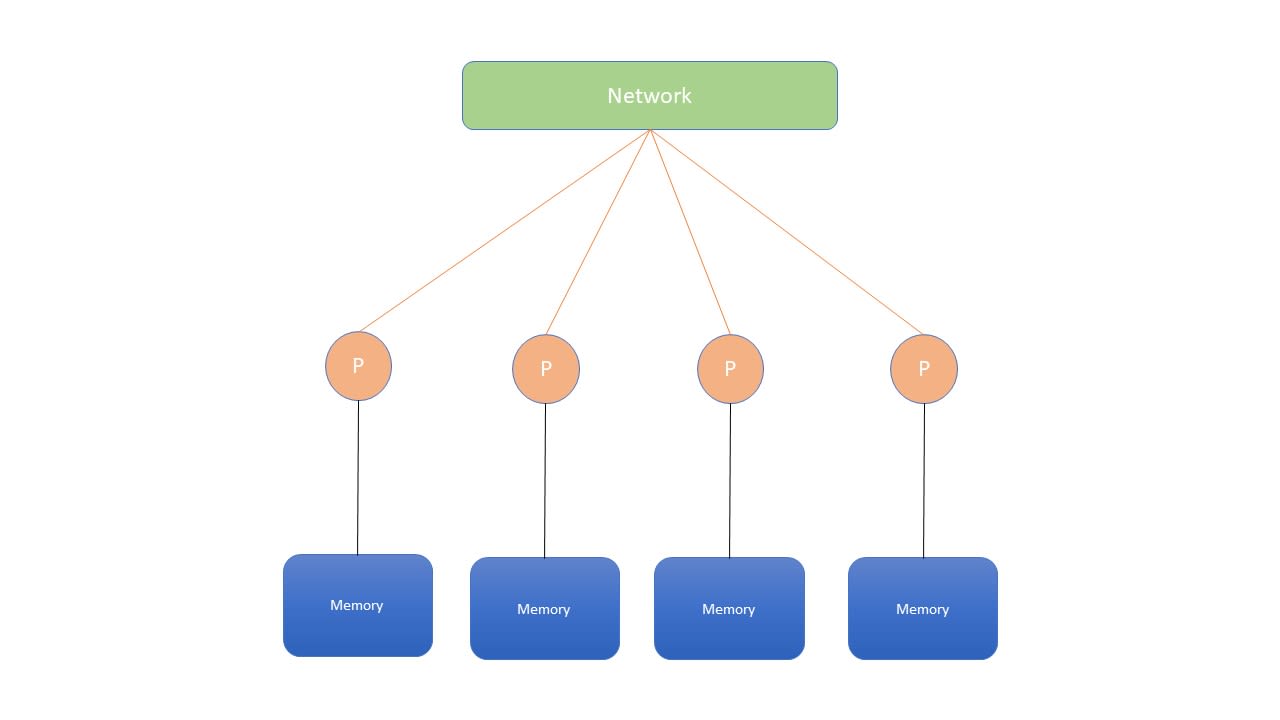
2- At various nodes levels: regarding the communication between the CPUs located on these separate nodes. These CPUs have also separated memory and they would need to explicitly communicate their data amongst them.
3- At accelerators levels (see section "Accelerator technology”).
4- At various levels of support for programming languages.
Message passing
Message passing is one of the many models of IPC (inter-process communication) which has proven very useful for multiple calculations on different computers. The message passing interface defines a standard suite of functions for these tasks.
A smart management of the entire supercomputer network is therefore crucial to make sure there are no conflicts and that the needs are still met. For weather and climate, operational forecasts are time-critical with jobs scaled-out to get the required performance, and the cost of exchanging data between separate nodes can become very expensive. Therefore it is important to limit the amount of communication to the minimum and to ensure that network and communication libraries are tuned to be as efficient as possible.
CHALLENGES & ENERGY EFFICIENCY
Over the years, the type of architecture and the way the supercomputers' elements have been connected to each others have changed dramatically due to different factors, such as:
Processor technology
Moore's Law (attributed to Gordon Moore, the co-founder and former CEO of Intel.) states that the number of transistors on a microchip doubles every two years. In the field of supercomputers, this means that more processing power can be given, using the same space and the same energy quantity. This has run up against a hard physical limit of transistor size and number on a chip.
(image: Moore's Law Transistor Count 1970-2020 - Moore's law - Wikipedia)

Cooling
This other factor is linked with energy efficiency. With the extreme power of supercomputer comes the extreme heat, and the need to cool the computing hardware. This means that a big share of a supercomputer’s energy is also used to run chiller units and fans to cool the computing hardware. Without an efficient cooling system, supercomputers cannot operate properly. Today, most supercomputers use water-based cooling systems.

Memory
Another essential aspect of a supercomputer’s architecture is the memory. With supercomputers, the way the data is stored near the processing unit is a critical design factor, as it also impacts the energy efficiency. Ultimately, moving data in and out a memory is up to ten times more energy-consuming than usual computing.
Energy consumption in perspective
A EuroHPC supercomputer like LUMI requires a power around 6MW (see November 2022 | TOP500). A wind turbine has a peak power of up to 5MW. The overall power requirement of a supercomputer equals therefore the power generated by one to three wind turbines on average, depending on the wind.

Mapping needs for energy efficiency
In the past, unused nodes were still consuming up to 80% of the supplied energy, even if they were completely idle. Different options have been considered to address this issue, such as adapting the speed of unused parts, working on the “active part management”, or reducing the accuracy of these chips as it has been shown they may consume only 10% of the energy of a chip that is guaranteed to give the expected number.
But for weather prediction sectors, working with high-failure rate chips is difficult as it jeopardises the entire installation.
To exploit the supercomputer system efficiently, mapping the needs in advance is essential. This means identifying what sort of information is needed on each node (wind, temperatures, …), and how one would need these nodes to communicate (when doing a global forecast for example).


Enhancing supercomputing power


Increasing computing capacity is key to improve the representation of Earth system processes in models, to run finer-resolution forecasts, and to improve the assimilation of weather observations.
This is the reason why the pursuit of increasing computing performance and energy efficiency has been at the forefront of climate and weather prevision research. As the need to push this high-performance to the next level is growing to meet society's needs, it is a whole transformation in how supercomputers are designed and their performance measured that is occurring, leading to what we call the "exascale era of supercomputing" revolution.
Resolution
For the global forecasts, increasing a supercomputer power means increasing the resolution by reducing the separations between points within the grid.
As an example, the resolution of the ECMWF global forecasts has increased over the years: from first operational medium-range forecasts in 1979, predictions were made for grid points separated by up to about 200 km. The grid point spacing has since gone down dramatically: it was for example about 60 km in 1991, 25 km/50 km for high-resolution/ensemble forecasts in 2006, and 9 km/18 km for high-resolution/ensemble forecasts in 2022. On average ECMWF has doubled its resolution every 8 years.
With giant leaps in supercomputing developments comes new components and other factors to take into consideration.
Accelerator technology
In the context of looking to speed-up processing-intensive operations while improving energy efficiency, alternative computing platforms came along known as "accelerators". Exploring how to best integrate these new platforms is an ongoing process with its share of technical adaptation challenges.
Some of the most well-known "accelerators" technologies include:
The graphics processing unit (GPU). A GPU is as a versatile single-chip computing machine, GPUs have been developed to satisfy broad calculation needs and were initially used in the computer graphics field for advanced and intensive calculations. The rapidly rising gaming industry and demand for fast, high-definition graphics have led to the steady growth of GPUs into highly parallel configurable devices.
But the potential of GPUs to perform mathematically intensive computations on very large data sets was noticed also for other computing areas. This is how supercomputers started integrating GPUs as part of their nodes and cabinets to become more efficient. Today, many of top supercomputers use both CPU and GPUs to make the most of both technologies.
Other platforms include also Tensor Processing Units (TPUs), designed from the ground up to speed up AI training. TPUs are specifically used for deep learning to solve complex matrix and vector operations. They must be paired with a CPU to give and execute instructions.
Field Programmable Gate Arrays (FPGAs ) are programmable chips that can be designed to implement any digital function or calculation by hardware. FPGAs consist of an array of logic gates that can perform any digital implementation desired by the developer.
Data Processing Units (DPUs) are new class of programmable processor that combines industry-standard, high-performance, software-programmable multi-core CPU; high-performance network interface; flexible and programmable acceleration engines.



Accelerators for weather and climate predictions
Switching from CPUs to these accelerators' technologies impacts the entire architecture of supercomputers and affects the softwares and working processes associated with it.
How to interact with this new architecture to get the best performance?
Adapting codes
Algorithms for GPUs are different then for CPUs, (this means that for exploiting optimal performance, the programming language may need to be different for compute intense kernels). While at first everything had to be rewritten for GPUs, softwares have evolved, allowing CPUs' codes to run on GPUs as well.
Programming models
For parallel calculation, a programming model allows to “translate" the initial code and language to execute different levels of calculation in parallel.
GPU Programming is a method of running highly parallel general-purpose computations on GPU accelerators. But one GPU has lots of different ways to be filled. This can therefore create a misalignment between the initial (code, language) levels and the GPU's increased possibilities.
Compilation
One of the final step for execution is called “compilation”, when the compiler gets in action.
However, compilers are adapted to support specific hardware, which also changes with GPU’s new architecture.
Parallelisation
Switching to accelerators technology also affects the way parallelism is applied as the algorithms initially used with CPUs for higher degrees of parallelism need to be changed.
This also requires new adaptations to manage the communication between the CPus and the accelerators.
For weather and climate applications, adapting to this new architecture is encouraged as it is promising faster simulations at a lower energy footprint. This is however possible only if the system is properly exploited as energy is saved per “computing flop” consumed and one needs to consider the acquisition cost as well over a given timeframe.
“You have to really efficiently use and exploit the potential offered by GPUs in order to reach the ultimate energy performance.”
Dr Nils Wedi, Digital Technology Lead for Destination Earth at ECMWF
Destination Earth


Destination Earth
Destination Earth (DestinE) aims at assessing local impacts of global processes. Through this initiative, the level of detail of measures and prediction needs to be increased.
In this context, DestinE needs intensive use of high-performance computing to run the highly complex simulations of the Earth system at the very high resolution of the digital twins, quantify uncertainty of the forecasts and perform the complex data fusion, data handling and access operations that the system will make available
This required computing capacities not yet achieved: it is estimated that DestinE’s digital twins will ultimately result in up to 352 billion points of information and 1 petabyte of data a day to produce simulations at about 1- 4 km horizontal resolution. For comparison, ECMWF’s current model produces 9 billion points and 100 terabytes a day for simulations at 9 km.


{kind=link}

On board with leading supercomputer platforms in Europe
With Destination Earth comes-in extremely complex simulation codes and the need to tap-into the most innovative platforms to run the first Digital Twins simulations at scale. In this context, a new partnering landscape has been taking shape pooling together the most advanced knowledge and resources in the field of supercomputing in Europe.
The ECMWF has joined forces with the European High Performance Computing Joint Undertaking (EuroHPC) to access some of the largest pre-exascale systems in Europe for the DestinE intiative.
Destination Earth first models will be adapted and optimised to run efficiently on three of the most powerful European supercomputer infrastructures:

LUMI
LUMI, hosted by Finland’s CSC IT Center for Science, with a measured Linpack performance of 309.1 (428.7 peak) petaflops per second.
(Image courtesy of LUMI)

Leonardo
Leonardo, hosted by Italy’s Cineca, with a Linpack performance of 174.7 (255.7 peak) petaflops per second.
(Image courtesy of Cineca)

MareNostrum 5
MareNostrum 5 of the Barcelona Supercomputing Centre (BSC).
(Featured image shows new site where MareNostrum 5 is being installed)
These three installations are very well positioned within the TOP500 list of the most powerful supercomputers in the world, positioning LUMI in the third and LEONARDO in the fourth place. When it comes to integrating cutting-edge and innovative technologies, each of them has its own configuration, working with clusters where separate "CPUs", "GPUs" (called the "booster" cluster) and "data access" groups are organised. For Destination Earth, this means adapting to different environments with its share of associated challenges. But advancing throughout brand new computing technologies also means the possibly to capture the successful paths that will unlock the next phase of highly precise simulations of the Earth system.
The way forward is to follow a distributed work where the first priority is to get the models running on the different platforms, producing the data, and then finally being able to manage the data which comes with the connection to the wider Destination Earth platform. The last phase will allow to access the three computing sites.
Some of the most important factors in this working process include:
Adapting CPU codes to programming needs of GPUs
This means there is the need to build workflows that are resilient and generate reproducible results also on machines that will be emerging in the future.
Message passing: consistent computing speed is essential when running forecast, so that it can run as fast as possible on these platforms. This adaptation effort is really one big element of Destination Earth as well in particular considering the coupling of different Earth System model components (atmosphere, ocean, sea-ice, waves, land-surface, atmospheric composition, etc).
Data assimilation: development work is occurring with ECMWF’s own supercomputing installation, as well as with associated tasks related to observation handling, fusing model and observational information in the process called data assimilation.
The Italian supercomputing institution Cineca has signed an agreement with the European Centre for Medium-Range Weather Forecasts (ECMWF) to cooperate throughout the first phase of Destination Earth on technical adaptation challenges.
With the Destination Earth initiative, a new chapter is started where HPC computing capacity is explored like never before to represent the global Earth-system physics as realistically as possible. By increasing computer power while improving energy-efficiency and maintaining affordability, it will be possible to reproduce the impacts of climate change and weather-induced extremes at scales that matter to society.
More information:
Video banner credit: ECMWF’s Atos BullSequana XH2000 supercomputer facility. See more Fact sheet: Supercomputing at ECMWF | ECMWF
Italy’s Cineca to accelerate Destination Earth’s innovative technology adoption (ecmwf.int)
We acknowledge the EuroHPC Joint Undertaking for awarding this project strategic access to the EuroHPC supercomputer LUMI, hosted by CSC (Finland) and the LUMI consortium, Marenostrum5 (Spain, BSC) and MeluXIna (Luxembourg) through a EuroHPC Special Access call.